Гертцель объясняет: "Причина, по которой С Г является более естественной комбинацией, кроется в том, что она закладывается на раннем этапе процесса словообразования ". Теперь можно понять, почему многие веб-документы не предоставляют поисковым системам убедительные послания. После линеаризации, можно обнаружить, что они "разговаривают" как дети. (Кстати, алгоритмы L-System, названные в честь Линдермеера - A.Lindermayer, использовались в течение многих лет при исследовании деревоподобных шаблонов).
"Сжигание деревьев" объясняет, почему повторение в документе терминов, наложенное на внутристраничные факторы или стратегии залинковки, не обязательно улучшит релевантность. Во многих случаях достигается прямо противоположный результат. Я бы рекомендовал поисковым оптимизаторам понемногу овладевать приемами работы с лексикографическими/словесными шаблонами, и включать стратегии линеаризации и локального анализа контента в их набор оптимизационных инструментов.
На рис.1 "сжигание деревьев" стало результатом неправильно позиционированного текста. Однако во многих случаях, это побочный эффект неэффективного веб-дизайна, плохого юзабилити или неправильного использования структуры HTML DOM (еще один тип дерева). Это еще раз подчеркивает рекомендацию W3C: html-таблицы должны использоваться для представления табличных данных, но не для дизайна веб-документов. В большинстве случаев, профессиональные веб-дизайнеры в состоянии заменить таблицы с помощью CSS (cascading style sheets).
"Сжигание деревьев" зачастую вызывает еще один феномен, который я называю "соперничеством удельного веса кейвордов" ("keyword weight fights"). Это повторяющаяся проблема, которая встречается при определении топика (topic spotting), при сегментации текста (на основании изменений в топике), а также при анализе топика. Совместное употребление сочетаний слов и словесных классов предоставляет важную информацию об используемом стиле изложения. Поэтому неправильно расположенные кейворды и текст без определенной тематической принадлежности затрудняют работу редакторов текста (будь то люди или роботы), которые должны составить достоверные заголовки и выдержки из документа.
Таким образом, "соперничество" неоправданно затрудняет процесс классификации документа условным редактором, который в течение этого процесса должен ответить на вопросы, подобные: "О чем этот документ или раздел?", "Какова тема или категория этого документа, секции или параграфа?", "Как этот блок ссылок соотносится с контентом?" и т.д.
Покуда линеаризация сводит на нет локализованные значения KD, индексация документа сотворила мифы вокруг этого параметра. Давайте разберемся, почему.
Токенизация, фильтрация и стемминг
Индексация документа представляет собой процесс трансформирования текста документа в репрезентацию текста, и состоит из трех шагов: токенизации, фильтрации и стемминга.
Во время токенизации, термины переводятся в нижний регистр, а знаки пунктуации удаляются. Правила остаются в силе, поэтому цифры, дефисы и другие символы должны парситься, как положено. За токенизацией следует фильтрация. В течение фильтрации, удаляются общеупотребимые термины и термины, которые не несут никакой семантической нагрузки (stopwords) . В большинстве IR-систем, выжившие термины еще больше прореживаются до образования общих стеблей или корней. Этот процесс известен как стемминг. Таким образом, исходный контент длиной l уменьшается до списка терминов (стеблей и слов) длиной l' (то есть, l' < l). Эти процессы описываются на рис. 2. Очевидно, что если линеаризация покажет, что вы уже "оптимизировали деревья", то поисковая система проиндексирует ваш исходный материал.
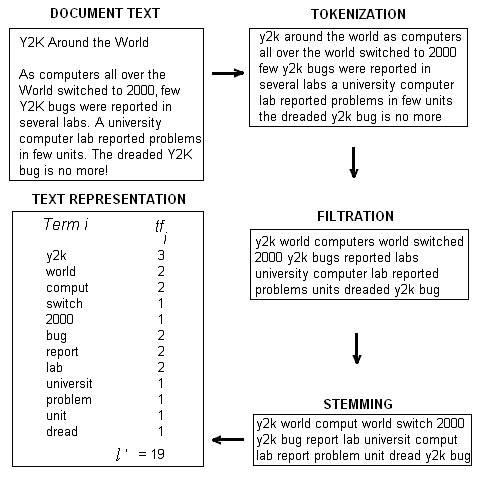 Рис.2. Важные шаги во время индексации документа: токенизация, фильтрация и стемминг
Рис.2. Важные шаги во время индексации документа: токенизация, фильтрация и стемминг
Подобные списки могут быть получены из отдельных документов, путем слияния, чтобы образовать индекс терминов. Этот индекс можно использовать в разных целях: к примеру, чтобы рассчитывать вес терминов, и представлять документы и запросы как векторы терминов в пространстве терминов.


